안녕하세요! Dev. Pluito 입니다.
정말 오랜만에 인사를 드리게 됐습니다! (최근 이런저런 준비하는 것들과 일들이 많이 생겨서 블로그를 많이 작성하지 못했네요..😭)
오늘은 회사에서 도입하기로 결정된 아파치 카프카에 대해서 그 특징을 알아보고 어떤 이유에서 매력적이었는지. 선택한 이유는 무었인지에
대해서 알아보는 시간을 가지겠습니다!
대상 독자
- 이 문서는 아파치 카프카 에 대해서 “들어만”본적 있거나
- 분산 환경에서의 이벤트 기반 Message Queue 사용에 익숙하지 않은 분들에게 적합한 문서입니다.
What is Kafka?
“아파치 카프카는 분산 이벤트 저장 및 스트림 처리 플랫폼” 이라고 사전적 정의에 명시돼있습니다.
하지만 단순히 사전적인 정의로만 카프카를 이해하고 설명한다면 필자는 단순히 Chat-Gpt의 설명을
그대로 읊어주는 대리인에 불과하겠지요. 좀더 자신만의 언어로 해석해보도록 하겠습니다!
카프카가 뭘까?
개인적인 생각으로, 카프카는 “MicroService환경과 같은 혹은 유사한 분산 환경에서 여러 개의 독립된 어플리케이션의 이벤트를 기반 비동기 데이터 통신을 위한 중앙 이벤트 스토리지 이다” 정도로 생각하였습니다
(여기서 스토리지 라고 말한 이유는 이후 설명에서 보강하도록 하겠습니다!)
조금 더 와닿는 설명이 없을까? 사내 서비스를 예시로 들어보자
브이캣 서비스의 시스템에서, 여러 개의 Application Server에서 발생하는 각종 이벤트 들에 대한
비동기 처리와 로그 수집 및 수집된 이벤트를 기반으로 한 배치 처리 등을 수행하기 위해 사용한다!
조금 더 직관적인 이해를 위해 자세하게 시나리오를 몇 개 들어보겠습니다.😀
- 시나리오 1
서버에 사용자가 비디오 렌더링을 요청하였다. (Event!)
서버에서 Kafka에게 사용자 렌더링 요청 이벤트를 발행하고. (Produce)
분산 환경에 있는 다른 서버가 Kafka에서 해당 이벤트를 가져와 Daily Render Count를 집계할 수 있다.(Consume)
이렇게 집계된 렌더링 카운트는 고객사의 과금을 위한 기준 데이터 등으로 유용하게 쓰일 수 있습니다.
- 시나리오 2
인증을 담당하는 서버에서 유저 정보가 갱신이 될때 이벤트를 생성하고, 유저 정보에 대해서 데이터를 유지해야 하는
Application들이 메시지를 소비하여 다시 유저 정보를 조회하여 유저의 최신정보를 유지합니다.
이외에도 많은 경우로 이벤트가 발생하고 그에따른 Consumer Application의 처리가 있을 것입니다.

Note: 주키퍼(Zookeeper)에 대해서는 별도로 다뤄보는시간을 가지겠습니다!
카프카의 주요 개념과 용어
토픽(Topic)
- 카프카에서 데이터 스트림은 토픽이라는 이름으로 구성됩니다. 토픽은 특정 주제나 카테고리에 관련된 데이터를 포함하며,
프로듀서(데이터 발행자)는 데이터를 특정 토픽으로 발행하고, 컨슈머(데이터 소비자)는 특정 토픽으로부터 데이터를 소비합니다. - 컨슈머나, 프로듀서가 논리적으로 공유하는 일종의 채널(Channel)의 개념으로 생각하시면 좀더 이해가 쉽습니다.
- 카프카에서의 이벤트는 영구적으로 저장되는 특징을 가졌고, 파일 시스템으로 예를 든다면 토픽은 폴더와 비슷하며
이벤트는 해당 폴더에 있는 파일들입니다.
프로듀서(Producer)
- 카프카의 프로듀서는 데이터를 생성하고 카프카 클러스터에 해당 데이터를 발행합니다. 프로듀서는 특정 토픽에 데이터를 쓰는
역할을 담당하며, 데이터를 일괄적으로 발행하거나 비동기적으로 발행할 수 있습니다. - 조금 더 와닿는 설명이 없을까? 사내 서비스를 예시로 들어보자 에서의 렌더링 요청을 받은 서버가 이 경우에 프로듀서가 되어
데이터를 발행하는 역할이라 생각하시면 됩니다.
컨슈머(Consumer)
- 카프카의 컨슈머는 토픽으로부터 데이터를 소비합니다. 컨슈머는 데이터를 읽어들여 자신의 애플리케이션 또는 시스템에서 처리하게 됩니다. 카프카는 컨슈머 그룹(Cnsumer Group)이라는 개념을 제공하여 여러 컨슈머가 하나의 토픽을 병렬로 처리할 수 있도록
합니다. - 조금 더 와닿는 설명이 없을까? 사내 서비스를 예시로 들어보자 에서의 통계 데이터를 집계하는 서버가 컨슈머의 역할을 수행한다고
이해하시면 됩니다. 컨슈머는 카프카로부터 전파된 이벤트 데이터를 리스닝하여 수신하면, 짜여진 로직에 따라 동작을 수행합니다
브로커(Broker)
- 카프카 클러스터를 구성하는 서버 유닛을 브로커라고 합니다. 브로커는 프로듀서로부터 발행된 데이터를 저장하고
컨슈머에게 데이터를 전달하는 역할을 수행합니다. 카프카 클러스터는 보통 여러 개의 브로커로 구성되며
데이터의 복제와 분산 처리를 담당합니다.
파티션(Partition)
- 토픽은 파티션으로 나누어질 수 있습니다. 파티션은 토픽의 물리적인 세그먼트로서
각각의 파티션은 순서가 있는 메시지 시퀀스를 저장합니다.
파티션은 병렬 처리와 확장성을 위해 사용됩니다.
각 파티션은 여러 브로커에 분산되어 저장되며, 파티션의 수는 토픽을 생성할 때 설정할 수 있습니다.

오프셋(Offset)
- 오프셋은 특정 파티션 내에서 메시지의 순서를 식별하기 위한 고유한 식별자입니다. 오프셋은 각 메시지가 파티션 내에서 어느 위치에 있는지를 나타내며, 컨슈머는 오프셋을 사용하여 파티션으로부터 메시지를 읽어들입니다.
대충 알긴 하겠는데… 그런데 왜 카프카를 선택했을까?
- 아파치 카프카 이외에도 Message Queue Solution으로써 대안이 되는 다른 요소들도 많이 존재합니다.



이런 솔루션들을 제치고.. Vcat에서는 Aphache KafKa 를 사용하기로 결정하였습니다... 왜일까요? 🤔
(마지막에 등장한 Amazon SQS는 vcat에서 이미 사용중인 솔루션입니다. 기존에 사용하고 있던 SQS 를 사용하지 않고 카프카를 선택했는지에 대한 이야기 또한 다음에 이어서 다루어 보겠습니다.)
결론부터 말하자면, 카프카는 분산 시스템에서의 로그 및 웹 사이트 활동 추적에 가장 Fit한 Solution이다!
- 개인적으로 이유를 정리해 본 결과. Vcat과 같은 분산 환경에서의 어플리케이션 사이의 비동기 데이터 통신의 솔루션으로 카프카를 선택한 이유는 파티셔닝 기반 토픽의 병렬 Production & Comsume 의 높은 데이터 처리량, 이벤트를 영속하여 오랜 기간동안 저장할 수 있는 장점 때문에 선택하지 않았나 생각이 듭니다.
- Message Queue 로서 사용하였을 때, 메시지가 consume이 되면 Queue에서 없애지 않는다는 장점 또한 시스템의 견고함에 유리하다는 장점도 한몫 한다는 부분도 있지요
- 현재 시점의 vcat 시스템은 어떤 메시지 큐 솔루션을 사용하더라도 잘 동작을 할 것으로 생각됩니다! 하지만 앞으로 규모가 커질
(sns-posting, 결제 프로젝트 등)때의 이벤트 처리량을 고려한다면, 카프카가 가장 매력적인 선택지가 아니었나 생각이 됩니다.
물론 카프카를 위에서 언급한 용도 이외에 다른 용도로도 충분히 사용할 수 있습니다.
그 부분은 필자가 카프카를 직접 사용하고 많이 맞아보며(?) 느낀점을 토대로 설명을 추가하도록 하겠습니다.
카프카가 무슨 특징을 가지고 있길래?
- 위에서의 결론에 대한 세부 설명을 카프카의 특징과 함께 다른 메시지 큐 솔루션들과 비교하며 부연설명을 해보겠습니다.
이벤트 영속
- 카프카의 개념에 대해서 설명한 대로, 카프카의 이벤트는 상위 개념인 토픽에 포함되어 실제 스토리지에 저장됩니다. 따라서 설정에 따라 저장되는 기간을 설정하여 이벤트를 영속할 수 있습니다.
- 비슷한 솔루션인 RabbitMQ에서는 이벤트를 영속하는 기능을 제공하긴 하지만, 주로 장애 복구나 내구성을 위한 목적으로 사용됩니다.
- 조금 더 자세히?
- 하지만 RabbitMQ의 주요 목적은 메시지 큐잉이며, 디스크에 메시지를 영속화하는 것은 주로 장애 복구 및 내구성을 위한 목적입니다.
RabbitMQ는 디스크에 메시지를 영속화하고 복구할 수 있지만, 이는 메시지를 파일로 직접 기록하는 것과는 다릅니다
Kafka는 이벤트의 처리량을 높이기 위한 목적을 중심으로 이벤트를 영속한다면,
RabbitMQ는 장애 상황에서의 안정성을 높이기 위해 영속합니다.
결론적으로 RabbitMQ와 Kafka는 서로 다른 목적으로 이벤트를 영속하게 됩니다.
RabbitMQ는 메모리에 저장된 메시지를 디스크에 비동기적으로 기록하여 영속성을 제공합니다.
이를 통해 RabbitMQ는 장애가 발생하거나 메시지 브로커가 다시 시작되는 경우에도
메시지를 보존하고, 메시지 손실을 최소화할 수 있습니다.
- 하지만 RabbitMQ의 주요 목적은 메시지 큐잉이며, 디스크에 메시지를 영속화하는 것은 주로 장애 복구 및 내구성을 위한 목적입니다.
- 조금 더 자세히?
병렬 처리를 위한 파티셔닝
- 카프카의 특정 토픽은 여러 개의 파티션을 가질 수 있습니다. 이벤트가 카프카로 발행이 됐을때, 카프카는 토픽의 설정된 파티션의 개수에 따라 이벤트를 복제하여 등록합니다.
- 복제본을 유지함으로써, 병렬처리 및 Message Waiting Latency를 상당 부분 줄일 수 있습니다.
- 브로커의 장애 상황에서도 안정적으로 고 가용성을 보장할 수 있습니다.
- 이런 특징으로, 카프카는 생성된 이벤트에 대해 컨슈머에게 at least once 를 보장합니다
- RabbitMQ에서는 파티션의 대한 지원은 하지 않습니다.
이런 위험이 있지는 않을까..?😱
- 특정 토픽에 대한 하나의 이벤트를 여러 컨슈머가 동시에 가져가면 어떻게 되는걸까? 중복처리가 발생하는거 아닐까?
- 메시지를 소비하던 컨슈머가 제 기능을 하지 못할때 발생할 수 있는 문제가 있을까?
- 이벤트를 파일로 저장한다는데.. 엄청나게 많은 이벤트들이 발생하면 스토리지가 부족해지진 않을까?
- 병렬 처리를 위해 이벤트를 중복해서 여러 파티션에 저장한다는데… 이미 처리된 이벤트에 대해서는 어떻게 할까?
- 카프카 브로커에 장애가 발생하면 어떻게 되는건가? Critical한 SPOF 아닐까?
- 메시지 자체가 네트워크에서 유실이 된다면..?
결론
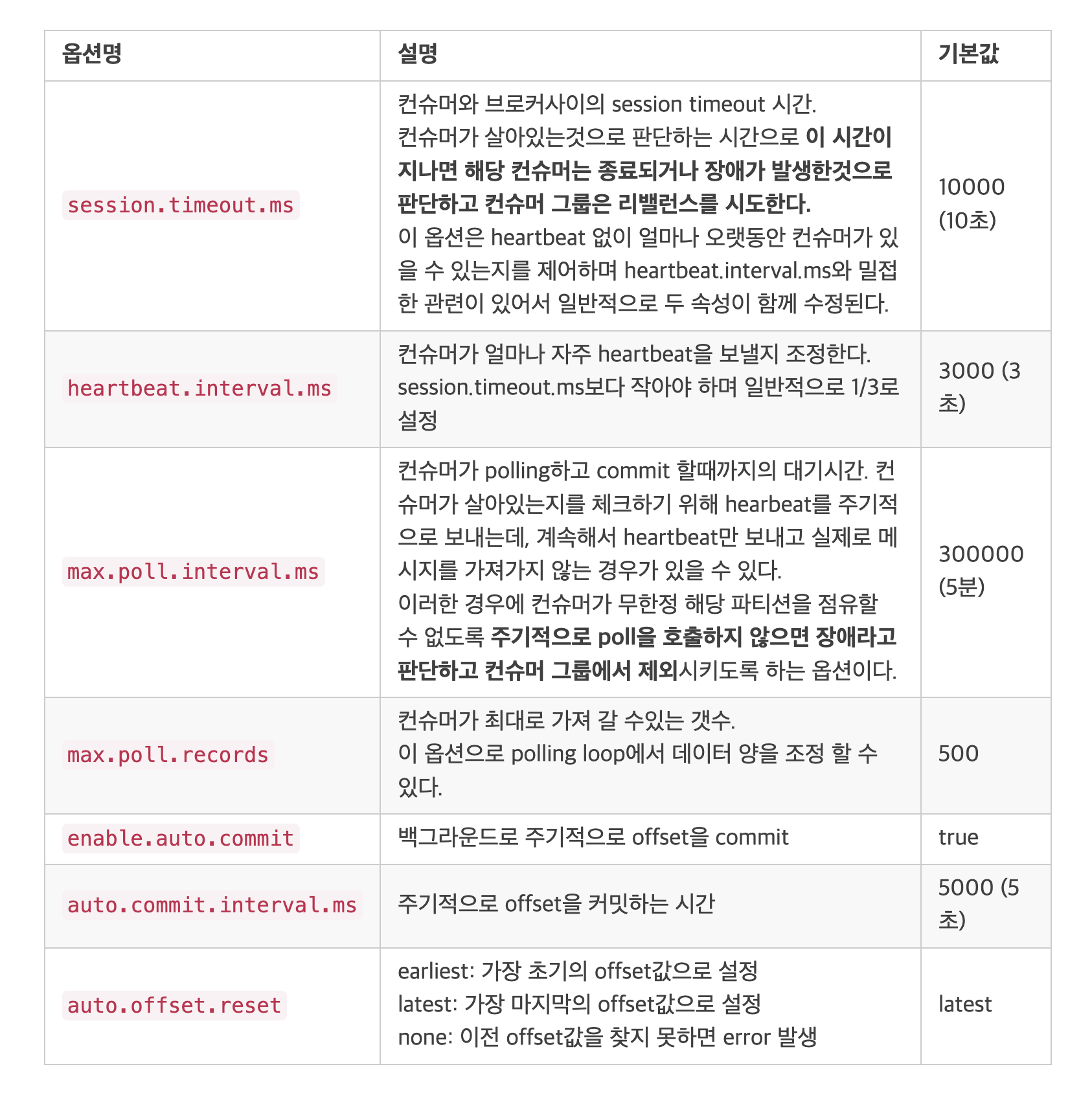
- 토픽 내의 파티션 개수와 컨슈머의 개수를 설정하는 부분은 많은 요소를 고려하여 결정해야한다!
- 한번에 polling 하는 이벤트의 개수와 처리 시간을 고려하여 컨슈머 재조정(rebalancing)이 발생되지 않도록 설정해야한다.
- 컨슈머 Application(혹은 시스템) 측에서 발생할 수도 있는 중복 이벤트 처리에 대해서 방어 로직이 존재해야한다.
'DevOps' 카테고리의 다른 글
| [NetWork] 포트포워딩과 로드밸런서 그리고 리버스프록시 (0) | 2024.03.04 |
|---|
